아주 간단한 langchain - langchain with RAG (1)
소개
최근 LLM들은 자연어 처리(NLP)를 통해 인간과 유사한 수준의 언어 이해 및 생성 능력을 보여주며 다양한 애플리케이션에 통합되고 있습니다. 그럼에도 불구하고, LLM은 여전히 몇 가지 근본적인 한계를 가지고 있습니다.
이번 글에서는 langchain과 Retrieval-Augmented Generation(RAG) 기술이 어떻게 이러한 LLM의 한계를 극복하는지에 대해서 말해보겠습니다.
목표
- Langchain은 무엇인가
- RAG은 무엇이고 어떻게 활용되는가
LLM의 현재 문제점과 그 영향
제가 여러 글을 읽고 직접 LLM을 활용한 application을 만드는데 느꼈던 문제점에 대해서 간단하게 공유하겠습니다.
최신 데이터 활용의 어려움
LLM은 대규모 데이터셋을 기반으로 사전 학습(pre-training)되며, 이 데이터셋은 실시간으로 추가하여 학습하기 어렵습니다. 이로 인해 LLM은 실시간으로 업데이트되는 최신 정보를 반영하는 데 한계를 가지며, 이는 특히 변화가 빠른 분야에서 생성된 내용의 정확성을 저하시킬 수 있습니다.
또한, 인터넷 검색을 통해 최신 정보를 수집할 경우, 검색 결과의 편향성이나 불확실성이 LLM의 출력에 영향을 미칠 수 있습니다.
학습되지 않은 정보에 대한 할루시네이션
할루시네이션(hallucination) 현상은 LLM이 학습 데이터셋에 없는 정보에 대한 답변을 만들어가는 과정에서 오류를 포함한 내용을 생성하는 것을 말합니다. 이는 신뢰성 높은 서비스를 기대하는 사용자에게 큰 문제가 될 수 있습니다.
데이터 학습에 대한 고비용 및 많은 시간 소모
LLM을 특정 도메인이나 맞춤형 데이터셋에 적용하기 위해서는 추가적인 학습(fine-tuning)이 필요합니다. 이 과정은 대량의 데이터 준비와 처리, 그리고 상당한 컴퓨팅 자원을 요구하며, 결과적으로 개발자에게 상당한 비용과 시간을 요구하는 부담으로 작용합니다.
Langchain
Core features
Langchain은 대규모 언어 모델(LLM)을 활용하는 애플리케이션 구축 과정을 간소화하기 위해 설계된 오픈 소스 프레임워크입니다. 다음과 같은 작업을 수행할 수 있도록 도구와 기능을 제공합니다.
- 다양한 데이터 소스와 LLM 연결
- 여러 데이터 소스에 대한 통합을 지원하여 간단하게 LLM과 연결할 수 있습니다.
- 높은 추상화 지원
- 높은 추상화로 인해 모델 변경 뿐만 아니라 다양한 integration에 대해서 큰 어려움없이 가능합니다.
- LLM 응답 맞춤
- 랭체인은 “체인”이라는 일련의 단계를 통해 LLM이 생성하는 출력을 조정할 수 있도록 합니다. 이 체인에는 텍스트 번역, 데이터 필터링 또는 기타 조작 작업이 포함될 수 있습니다.
- chain은 요청에 대해서 단계적인 실행을 지정할 수 있는 그 과정 중에서 번역 뿐만 아니라 여러 데이터 조작이 가능하기 때문에 질문이나 답변들에 대해서 간단하게 조작이 가능하다.
langchain을 이용한 LLM을 한계 극복
갑자기 langchain을 이야기한 이유는 이전에 말했던 LLM이 가지고 있는 문제점들을 완벽하지 않아도 해결하는데 큰 도움을 받을 수 있습니다.
- 실시간 데이터 통합
LangChain은 LLM과 외부 데이터 소스를 연결하는 메커니즘을 제공합니다. 이를 통해 LLM이 실시간으로 업데이트되는 데이터를 활용할 수 있게 되어, 최신 정보를 반영하는 능력이 향상됩니다. 예를 들어, LangChain은 API 호출을 통해 최신 뉴스, 주식 시세, 날씨 정보 등을 실시간으로 가져와 LLM의 응답에 포함시킬 수도 있으면 제공되는 tools를 통해서 외부에 있는 데이터를 쉽게 가져올 수도 있습니다.
- 할루시네이션 감소
LLM이 만든 데이터를 외부에 있는 정보와 비교하는 과정을 통해서 신뢰도 있는 정보를 사용자에게 제공할 수 있습니다. 혹은 유저가 추가적으로 학습한 정보를 바탕으로 Langchain이 대답할 수도록 하는 기능을 통해서 사용자가 원하는 정보를 더욱 정확하게 제공할 수도 있습니다.
- 비용 및 시간 효율성 증대
내가 원하는 데이터를 학습하는데 있어서 fine-tuning을 하지 않더라도 Langchain에서는 외부 데이터 소스를 이용한다던지 사용자가 원하는 정보를 기반으로 대답할 수 있는 기능들을 제공하고 있습니다. 그런 기능을 통해서 fine-tuning이 없이도 사용자가 원하는 정보를 반환할 수 있게 도와줍니다.
그 외에도
제가 위에서 소개한 Langchain에는 다양한 기능이 있고 큰 장점들이 존재합니다. 그리고 그런 기능들은 고도화되고 custom이 가능한 chatbot, search engine, Q&A system, text summanry service, transfer system을 제공할 수 있도록 도와줍니다.
langchain에 대해서 추가적으로 궁금하신 경우 인터넷에 다양한 article이 존재하며 공부해시면 더욱 도움이 될 것 같습니다. 개인적으로는 공식 문서가 빈약하여서 회사나 개인이 정리한 내용이 더욱 도움이 되었던 것 같습니다.
RAG(Retrieval-Augmented Generation)
RAG란 무엇인가
Retrieval-Augmented Generation (RAG)은 최신의 자연어 처리 기술 중 하나로, 기존의 대규모 언어 모델의 한계를 극복하기 위해 고안되었습니다. RAG는 문서 검색(retrieval)과 생성(generation)을 결합한 모델로, 질문에 대한 답변을 생성하기 전에 관련 문서를 검색하여 해당 정보를 활용합니다. 이를 통해 모델은 학습 데이터셋에 없는 최신 정보를 반영하거나, 더 정확하고 상세한 답변을 생성할 수 있습니다.
RAG는 두 가지 주요 구성 요소로 이루어져 있습니다: 하나는 문서를 검색하는 retriever이고, 다른 하나는 검색된 문서를 바탕으로 답변을 생성하는 generator입니다. 문서 검색을 한 결과를 활용해서 답변을 만드는데 사용함으로써 더욱 정확하게 사용자가 원하는 답변을 얻을 수 있는 것입니다.
RAG 시스템을 구성하고 설계하는데는 embedding과 vector storage(vectordb)의 개념에 대해서 이해해야 합니다. 해당 내용은 이번 글에서 다루기 어렵다고 판단하여서 간단하게 소개하겠습니다.
embedding
embedding은 단어, 문장, 문서 등을 고차원 공간에서 저차원의 밀집 벡터로 변환하는 과정입니다. 정말 간단하게 말한다면 우리가 인식하는 언어 및 텍스트를 컴퓨터가 다른 것들과 비교할 수 있도록 vector라는 배열에 저장합니다. 해당 배열에는 float number가 많이 들어있는 배열입니다. 밑에는 예시입니다.
text="이 article은 langchain과 RAG와 관련된 article이야."
embeddingResult=embedding(text)
print(embedding[0]) // 0.111111
print(len(embedding)) // 1024
print(embedding) // [0.111111, 0.9123121, 0.300001, ..., 0.97342, ...]
우리가 특정 문서를 기반으로한 응답을 원하는 경우 우리는 특정 문서를 모두 embedding하여서 저장합니다. embedding된 vector들을 파일로 저장할수도 있고 특정 remote storage나 db에도 저장할 수도 있습니다. 그리고 질문으로 온 텍스트를 embedding해서 우리가 저장해둔 vector들과 비교(계산)을 하여서 문서에서 가장 연관성이 높은 문서에 내용을 가져옵니다.
가져온 문서를 LLM에 요청을 할때 같이 첨부하여서 프롬프트 엔지니어링과 비슷한 in-context learning를 하도록 하여서 우리가 원하는 답변을 만들도록 합니다.
여러 조각을 나누어서 embedding하여서 저장하는 것은 model에 요청을 할때 첨부할 수 있는 최대 단어(정확히는 token) 수가 정해져 있습니다. 아무리 많은 데이터를 LLM에 보내고 싶어도 한번에 보낼 수 있는 양이 정해져 있기 때문에 그것을 고려해서 작은 단위로 문서를 나누어서 embedding하고 저장하게 됩니다.
VectorDB
embedding에서 설명했던 내용에서 우리는 문서를 embedding에서 파일로도 저장할 수 있고 db에도 저장할 수 있습니다. 여기서 vectordb는 문서를 embeddings한 vector들을 저장하고 있으며, 유저 요청으로 들어온 질문에 대해서 embedding하여 가장 유사한 문서의 embeddings를 빠르게 검색할 수 있도록 최적화되어 있습니다.
정말 다양한 db에 vector들을 저장할 수 있습니다. mongodb, redis 뿐만 아니라 opensearch와 같은 곳에서도 저장할 수 있습니다. 하지만 vectordb들은 다른 nosql에 비해서 높은 성능과 관리에 대해서 부각하여서 설명하고 있습니다.
Langchain with RAG
langchain은 다양한 데이터 소스에 대해서 연결하는데 장점이 있습니다. 그런 장점은 RAG 시스템을 만드는데 큰 도움을 줄 수 있으며 LLM을 활용한 application 구축하는데 큰 도움이 줄 수 있습니다.
밑에 있는 내용은 langchain과 함께 동작하는 RAG 시스템에 대한 실행 flow입니다.
step 1) embedding data and store to vectordb
데이터 셋업을 위해서 존재하는 단계입니다.
어떤 서비스같은 경우 해당 단계와 step2에 있는 단계가 동시에 진행되는 것처럼 보일 수 있지만 반드시 step2 전에 선행되어야되는 단계입니다.
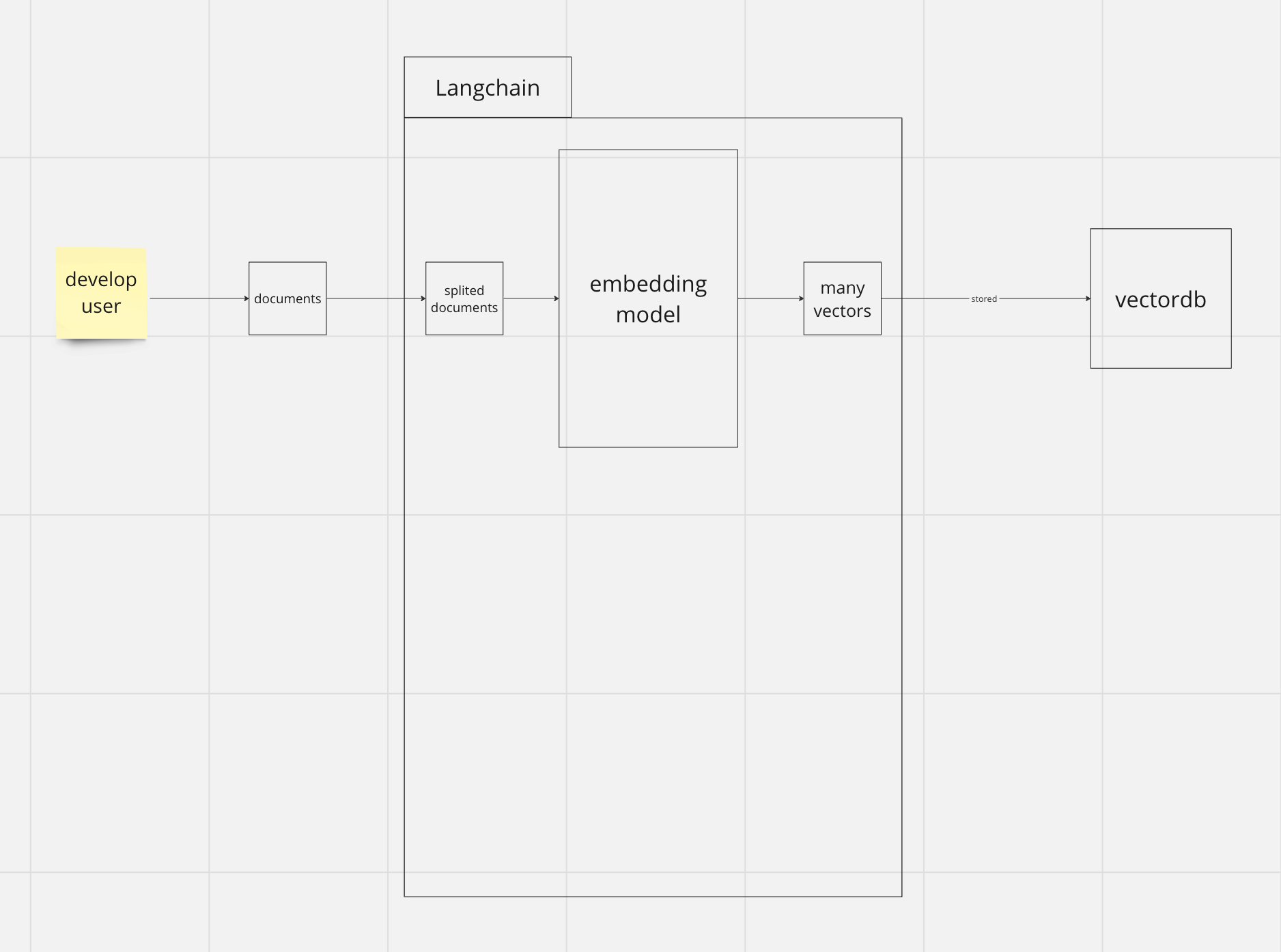
- developer나 user가 LLM이 활용했으면 하는 데이터를 전송합니다.
- 해당 데이터를 잘게 짜릅니다.
- 그것을 embedding model을 통해서 많은 vector로 만듭니다.
- 해당 데이터를 vectordb에 저장합니다.
step 2) embedding user input and take related documents
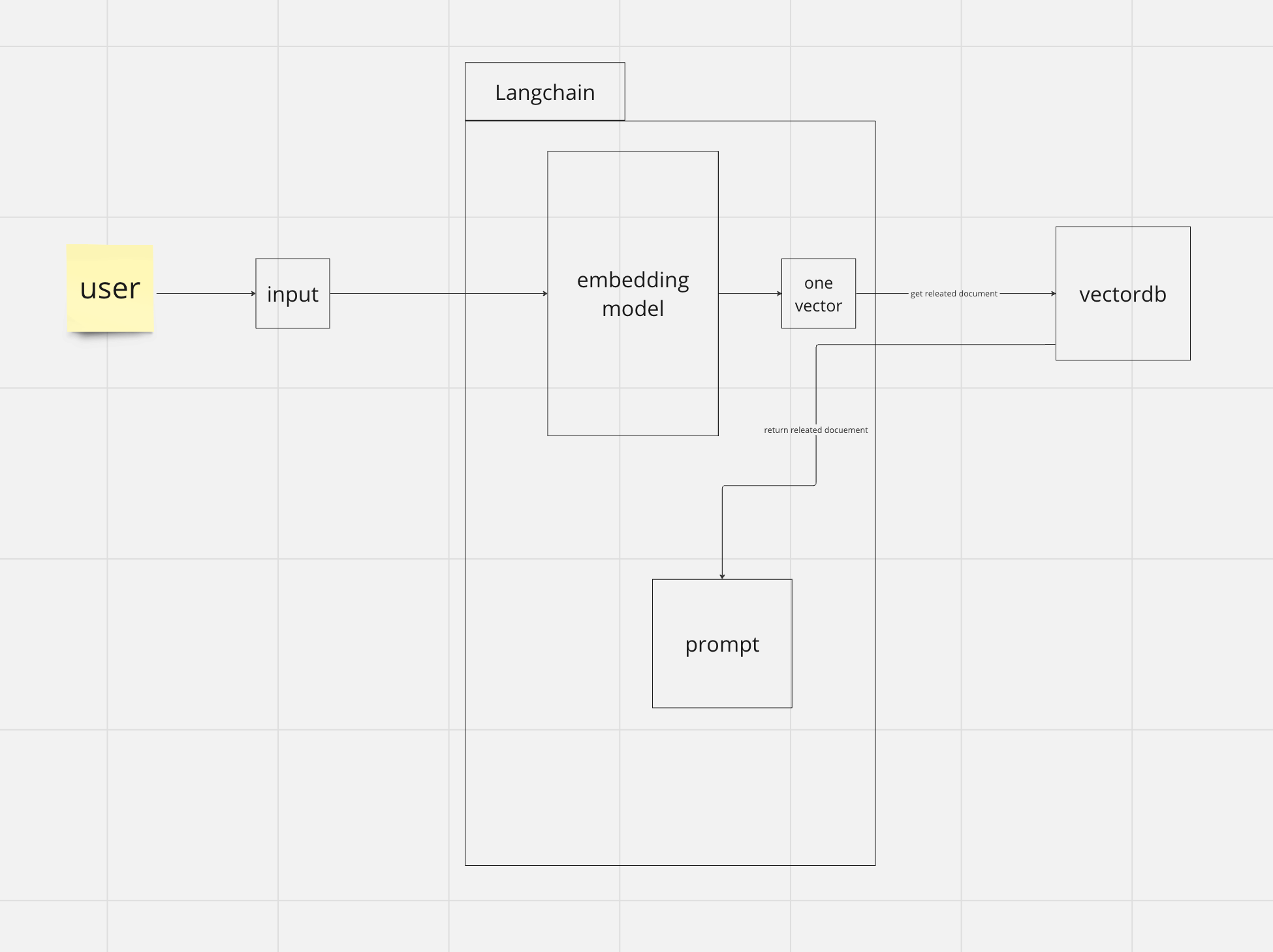
- user는 자신이 원하는 질문(프롬프트)을 입력합니다.
- 해당 질문을 embedding model을 이용해서 vector 하나를 만듭니다.
- 해당 vector을 vectordb로 요청을 하여서 가장 연관성이 높은 vector을 찾고 해당 vector의 content를 받아옵니다.
- 응답받은 content를 프롬프트와 합칩니다.
step 3) request LLM with user input and related documents from vectordb
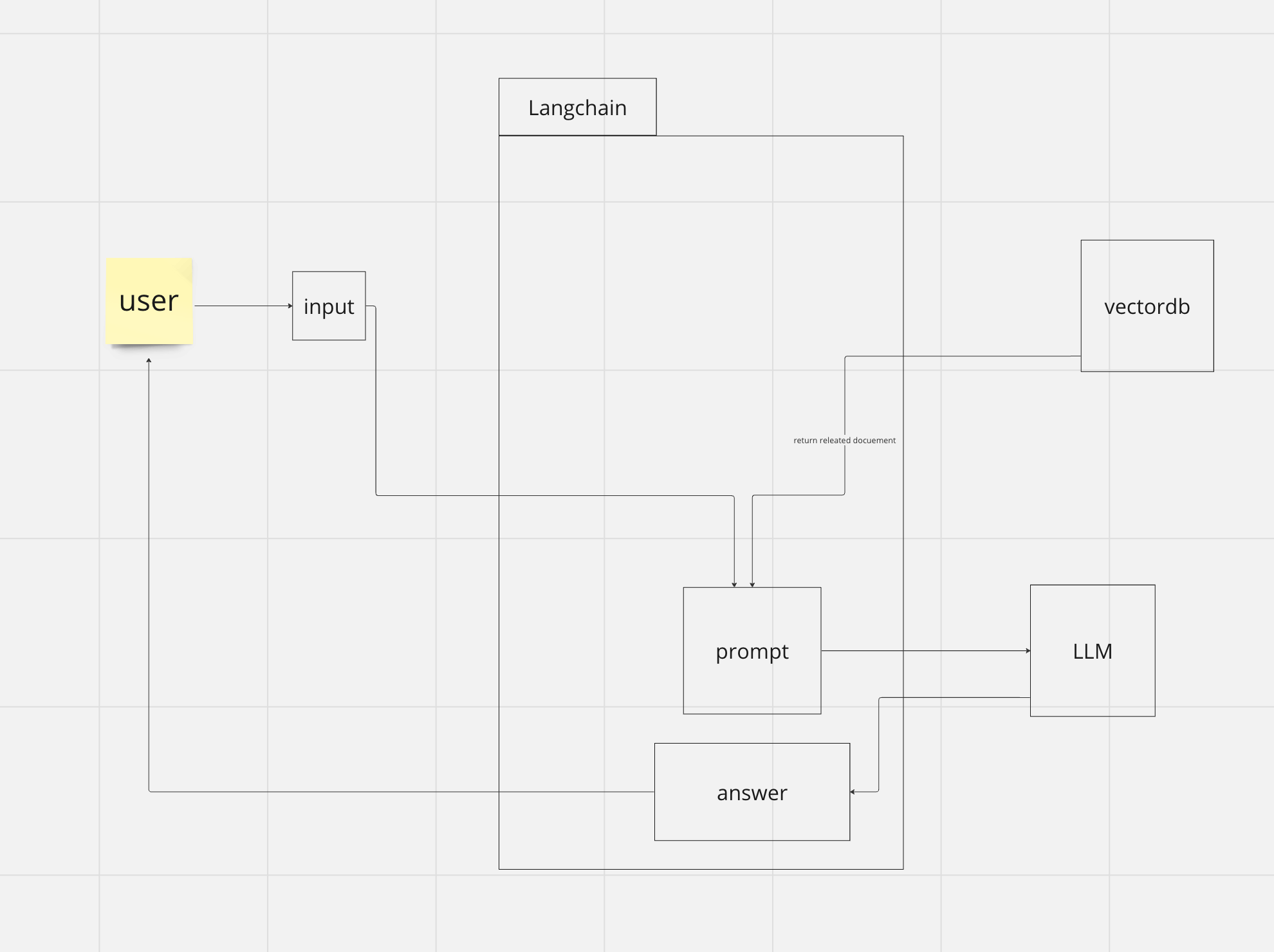
- user의 입력과 vectordb를 통해서 얻은 content를 합쳐서 prompt를 만듭니다.
- 해당 프롬프트를 LLM에 요청합니다.
- 그것에 대한 응답을 user에서 반환합니다.
total
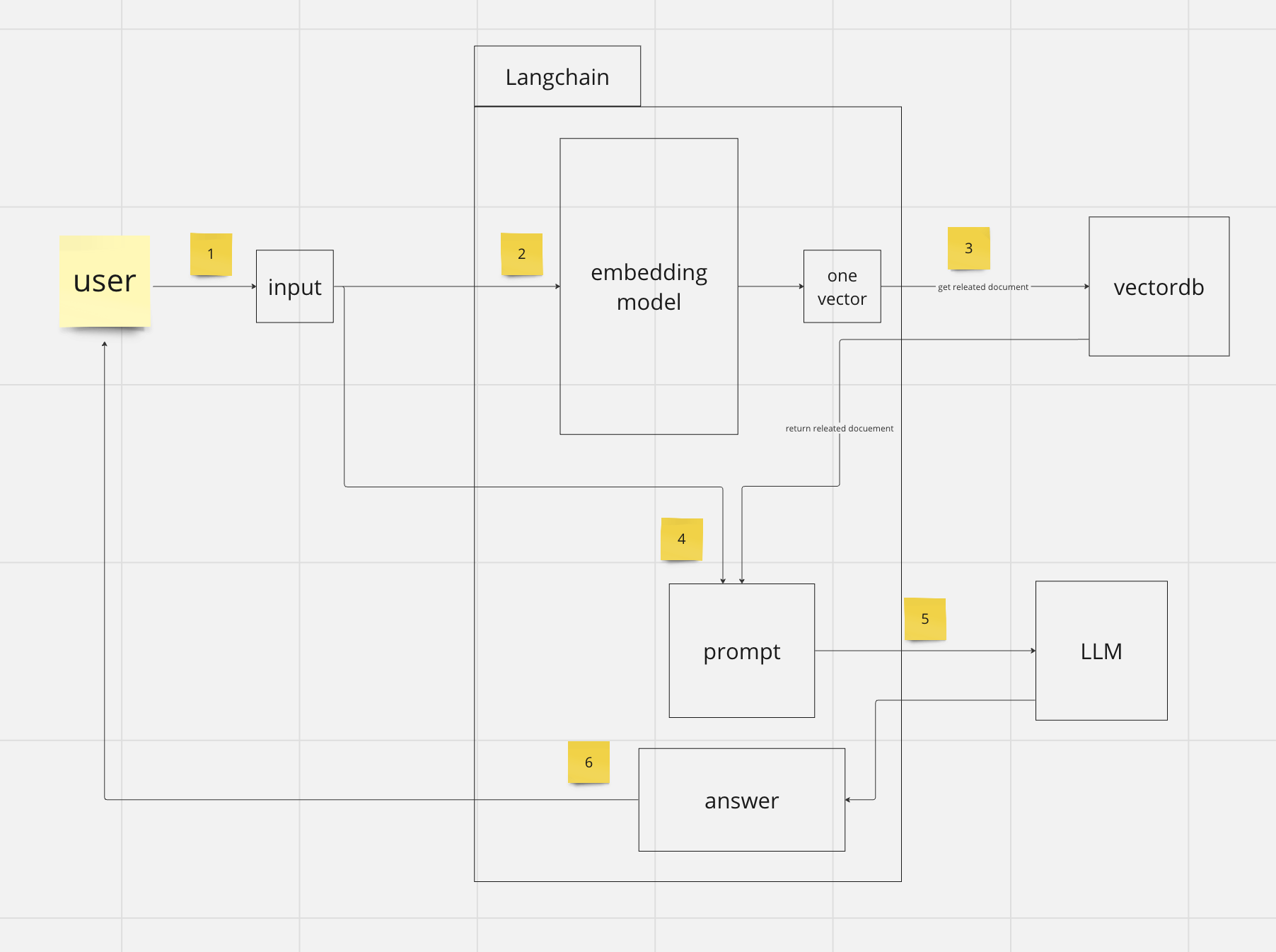
전체적인 그림으로 보게되면 위에 있는 그림과 같이 동작합니다.
conclusion
RAG를 이용하면 LLM를 활용하여 application을 만들때 발생할 수 있는 여러 문제점들을 해결할 수 있습니다. 그 과정에서 langchain를 이용하게 되면 더욱 LLM application 만들때 큰 도움이 됩니다.
이번 글에서 코드를 사용하지 langchain과 RAG에 개념에 대해서 간단하게 설명했습니다. 다음 글에서는 langchain를 이용하여 RAG를 어떻게 활용할 수 있는 코드를 이용해서 설명하겠습니다.

Leave a comment